잡담.
자주 듣는 얘기가 있다. 어떤 일이 A, B, C, …, Z 이렇게 순차적으로 이뤄진다고 할 때, 나는 A 설명했다가, B, C, ..,D까지 스킵하고는 E를 설명했다가, F를 한참 설명하다, 다시 B가 필요해진 것 같아 B를 설명하는 식이라고 한다. 한두 명만 이런 얘기를 하는 게 아니라, 나랑 가깝게 일을 한 모두가 비슷한 얘기를 하는 걸로 봐선, 좀 문제가 있는 것 같다.
상대방과 내가 같은 지식과 한계를 갖고 있을 것이라는 전제를 갖고 설명하는 듯한 느낌이다. 내가 쉬운 부분은 상대한테도 쉽고, 내가 어려운 부분은 상대방도 어렵고. 사회적 관계에서만이 아니라 일에서도 공감능력은 중요한 것 같다. 게다가 이런 건 노력해도 잘 나아지지 않는다고 한다……..
오픈 소스에 대한 개인적인 생각
솔직히 자기과시욕을 제외하면, 오픈소스를 왜 하는 이유를 잘 모르겠다. 회사 입장에서는 더더욱 잘 모르겠다. 구글이 왜 오픈 소스를 하는가같은 글을 여러 개 읽어봐도 잘 이해가 가지 않는다. 그럼에도 내가 정말 정말 가끔씩, 오픈소스를 하는 이유는 다음과 같다. 멋있어 보여서도 사실 크지만, 그걸 제외
내가 생각하는 오픈소스의 장점
1. 공부 & (경력이 적은 사람의) 포트폴리오를 대신함.
토이 프로젝트를 만들어서 포트폴리오로 사용하는 사람들이 많다. 나도 예전엔 그랬었는데 요즘은 잘 하지 않는다. 무엇인가를 배울 때엔 작은 규모의 프로젝트가 도움이 많이 되는 것은 맞다. 다만, 그런 프로젝트의 가장 큰 문제는 경험이 없으면 쓸모 있는 프로젝트를 하는 것이 불가능하다는 점이다. 첫 번째로, 나같이 창의력 없는 4차 산업혁명엔 전혀 맞지 않는 사람에게는 좋은 주제를 잡는 것이 실제 프로젝트 내용보다 더 어려울 수도 있다. 일을 하는 도중에 누군가에게 피드백을 받기도 힘들다. 경험이 많은 사람의 경우 그런 피드백이 없어도 성공적으로 무언가를 만들어낼 수 있다고 생각하지만, 나 같은 신입 찌랭이 프로그래머에게는 힘들 것 같다. 오픈소스 활동은 이 부분에서 포트폴리오용 프로젝트보다 유리한 점을 많이 갖고 있다. 거인의 어깨 위에서 일을 시작할 수 있다는 점이다. 창의성 없어도, 자신의 프로그래밍 스킬을 발휘할 수 있으며, 이를 타인에게 보여주고 리뷰도 받을 수 있다.
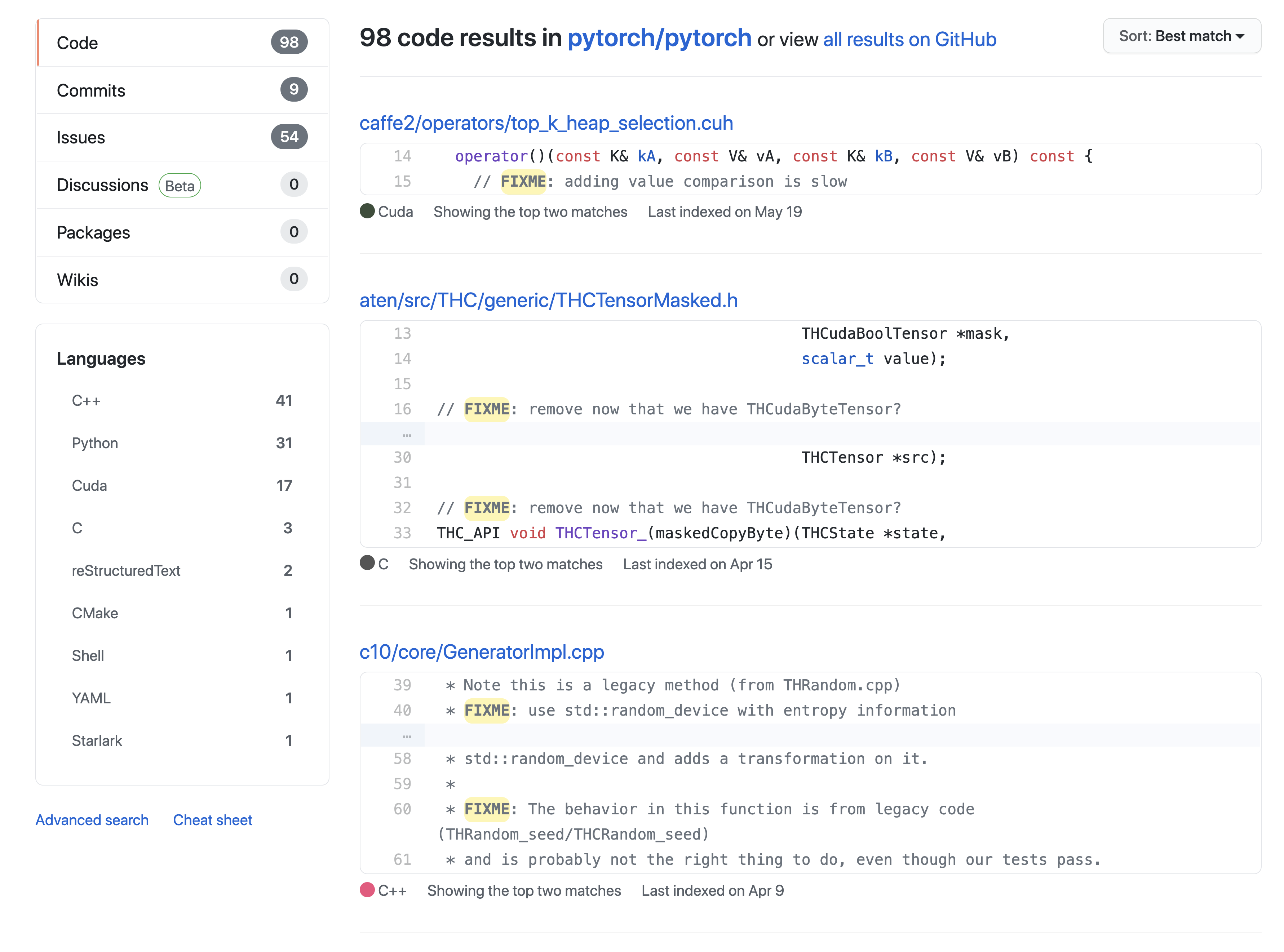 pytorch 코드 내에 FIXME로 검색한 결과이다. 저 중 몇 개는 분명 그리 어렵지 않을 것이고, 초보 프로그래머도 기여를 할 수 있을 것이다.
pytorch 코드 내에 FIXME로 검색한 결과이다. 저 중 몇 개는 분명 그리 어렵지 않을 것이고, 초보 프로그래머도 기여를 할 수 있을 것이다.
사실, 더 중요한건 내가 한 일에 대해 리뷰를 받을 수 있다는 점이다. 협업 경험이 적은 나 같은 초보자에게는 가장 간절한 부분이다. 나보다 경험이 많은 사람에게 내 코드롤 보여주고, 아이디어를 교환하는 과정은 대학교에서 배우지 못했다. 내 주변 학생들은 나보다 실력이 압도적으로 뛰어나지 않았고, 그렇게 해줄 수 있는 교수나 선배들은 정말 바빴다. 사실 내가 씹아싸라 친구가 없어서 그랬을지도 모르겠다…
2. 꼬우면 내가 하지
(내가 기계학습을 공부하고 있어서 다른 분야는 어떤지 모르겠다). 텐서플로우던, 파이토치던 그다지 완벽하지 않다. 이를 만든 사람들이 훌륭하지 않아서가 아니라, 훌륭함에도 불구하고. 암튼, Tensorflow에서 어떤 함수의 Gradient가 정의되지 않았다는 에러를 마주쳤을 땐 적당히 미분을 해서 그 식을 구현해서 처리할 수 있을 것이다. 단점은, 내가 잘 모르는 분야에 대해서는 (VS Code에서 기능상 한계를 찾았는데, 난 Electron은커녕 javascript도 해본 적이 없다면?) 아무 의미가 없다는 점이다.
 기능이 없어서 안될 때
기능이 없어서 안될 때
Example
암튼 내가 생각하는 오픈 소스의 장점 두 가지를 얘기했으니, 실제 예시를 통해 정말 이런 장점이 존재하는지, 그리고 초보 프로그래머에게 어떤 도움이 되는지 살펴보자. 초보라는 딱지를 굳이 붙인 이유는 내가 초보라서 그렇다.
문제 발견
위의 (2)와 같은 상황이었다. Deep generative ranking for personalized recommendation 논문을 재현하려고 했었다. 논문에서 (내 생각에) 가장 큰 컨트리뷰션은 user-item preferences를 Beta distribution으로 생각하고, 이 분포 자체를 sampling하여 학습하자는 아이디어인 것 같다. 암튼,일반적인 Normal distribution과는 다르게, Beta distributinon의 sampling을 이용한 분포 업데이트는 조금 까다로웠고, 감마함수의 n차 도함수(Polygamma function)을 필요로 했다. 근데 PyTorch에서는 감마 함수의 N’th order derivative를 구현해놓지 않고 있었다(order of 1까지 구현되어 있었음).
해야 하는 일을 정의하기.
암튼, 텐서플로우에선 이게 이미 구현되어 있다는 것을 곧 찾아냈고, Scipy에서도 같은 기능을 제공한다는 사실을 알아냈다. 저 두 구현체 모두, cephes(https://www.netlib.org/cephes/)라는 라이브러리의 Copy-Paste라는 사실도.
또한 파이토치의 많은 부분이 Cephes로 되어 있다는 사실도 알아냈다. 그럼, 내가 할 일은 Polygamma를 Scratch부터 구현하는 것이 아니라, 적당히 Cephes 코드를 고치는 것이라는 생각이 들었다. 딱히 Polygamma에 대한 내용을 이해할 필요도 없는 간단한 일이었다.
가장 좋았던 건, Polygamma에 대한 Interface가 모두 만들어져 있었다는 점이다. n=1인 경우를 제외하면 NotImplementedError를 던지게 되어 있었다.
구현하기 & PR 날리기
이 부분은 간단했다. C로 되어있는 library를, template을 이용한 함수로 바꾸고, 몇몇 interface용 함수들을 구현했다. 조금 복잡했던 부분은 Cuda 구현이었다. 다행히도 그 파일 내에 같이 구현된 다른 코드들을 대충 봐 가면서 거의 복붙을 했는데 별 이상한 점이 없었다.
공부가 된 건데, 내가 생각하는 거보다 테스트/의사결정/코드에 대한 기준이 엄청 높았다. 사실 여느 회사에서도 다들 이렇게 하는 것 같지만.
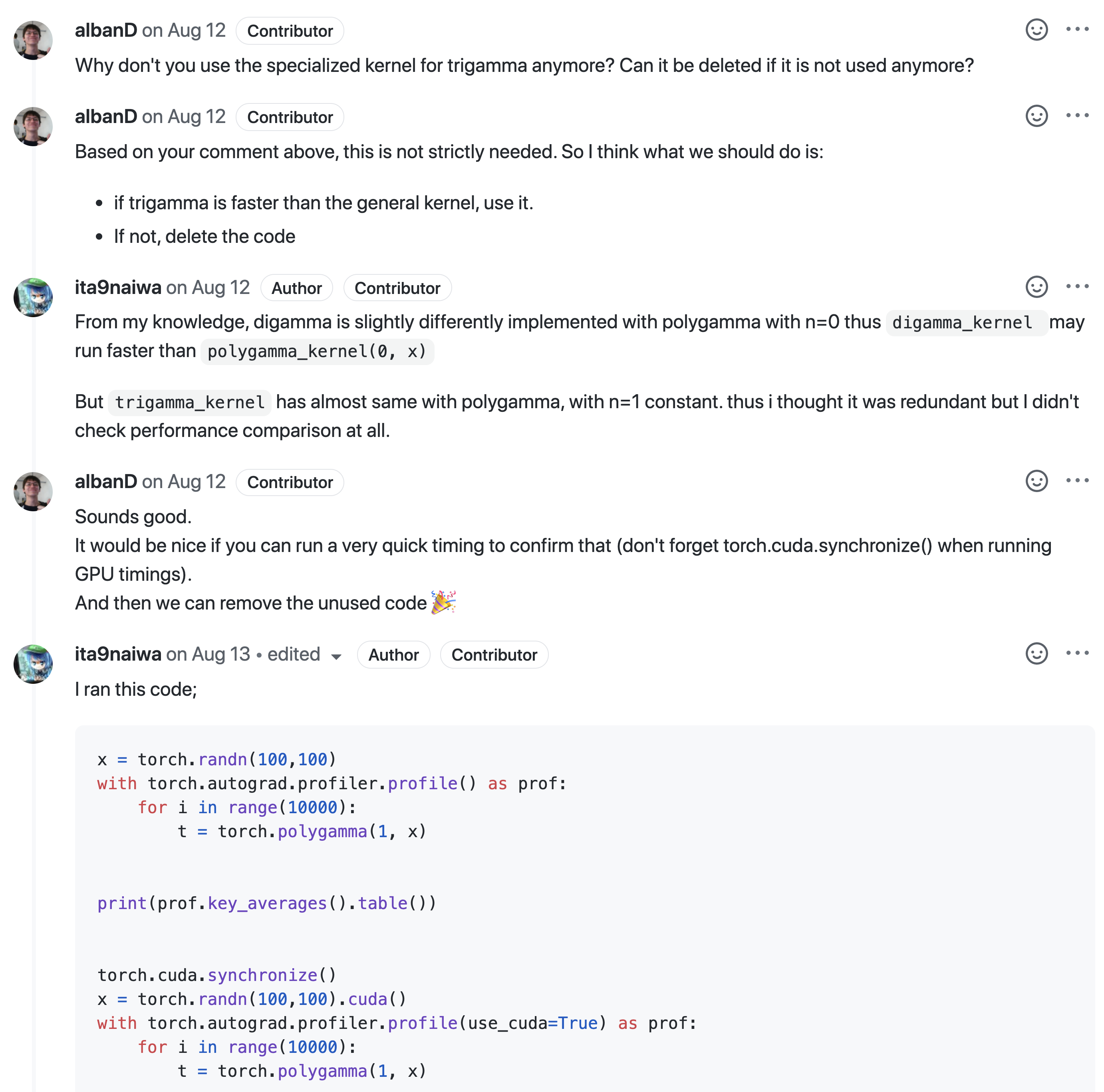 코드 리뷰 중 일부.
코드 리뷰 중 일부.
아마 코딩을 세상에서 가장 잘 하는 그룹 중 하나(사실 확실하진 않다)의 사람에게 코드 리뷰를 받는 경험은 어찌 됐건 도움이 되는 것 같다. 매일매일 이 정도 텐션을 갖고 프로그래밍을 대했다면, 더 잘 하는 엔지니어가 되어 있었을 텐데, 허비한 시간이 아깝다.
결론(배운 점)
- 공부 & 포트폴리오를 대신함
PyTorch 개발진이 사용하는 Python 규칙에 대해 어느정도 이해한 것 같기도 하고 아닌 것 같기도 하고. 딥러닝이니, 강화 학습이니 하는 Fancy한 단어들 뒤에는, 사실 80년대 물리학과/수학과/전산학과 대학원생이 마감에 쫓겨가며 만든 Fortran/C 코드가 숨어있다는 사실을 깨닫게 되었다.
- 꼬우면 내가 하지
감마 함수를 PR한 뒤 머지되기 전에, 결국 처음 구현하려고 했던 논문을 파이토치로 구현했다. 생각보다 성능이 나오지 않는다는 사실을 깨닫고, 시간을 많이 허비했구나 하는 생각이 들었지만, 뭐, 이거 하면서 많이 배웠으니 그걸로 괜찮겠지 하는 생각이었다.
 사실 남는 건 자기과시 뿐…
사실 남는 건 자기과시 뿐…
사실, 위에서 쭉 얘기했던 모든 장점을 제외하더라도 가끔 하면 재밌는 짓이라서 ‘ㅅ’…
雑談。
よく言われることがある。ある物事が A、B、C、…、Z と順番に進むとしたら、僕は A を説明したあと B、C、..、D まで飛ばして E を説明し、F をしばらく説明したかと思えば、また B が必要になったような気がして B を説明する、という具合らしい。一人や二人だけがこう言うのではなく、僕と近い距離で仕事をした人がみんな似たようなことを言うところを見ると、少し問題があるようだ。
相手と自分が同じ知識と限界を持っているという前提で説明しているような感じだ。僕にとって簡単な部分は相手にとっても簡単で、僕にとって難しい部分は相手にとっても難しい、と。社会的な関係だけでなく、仕事でも共感能力は重要なようだ。しかも、こういうのは努力してもなかなか良くならないらしい……..
オープンソースについての個人的な考え
正直、自己顕示欲を除けば、なぜオープンソースをするのか、その理由がよく分からない。 会社の立場ならなおさらよく分からない。Google はなぜオープンソースをするのかのような文章をいくつも読んでみても、よく理解できない。それでも僕が本当に本当にたまにオープンソースをする理由は次のとおりだ。格好よく見えるからというのも実際かなり大きいが、それを除いて
僕が考えるオープンソースの長所
1. 勉強 &(経歴の浅い人の)ポートフォリオの代わりになる。
トイプロジェクトを作ってポートフォリオとして使う人は多い。僕も以前はそうだったが、最近はあまりやらない。何かを学ぶとき、小規模なプロジェクトが大いに役立つのは確かだ。ただ、そういうプロジェクトの最大の問題は、経験がなければ役に立つプロジェクトを作ることが不可能だという点だ。第一に、僕のように創造力がなく、第4次産業革命にはまったく向いていない人間にとっては、良いテーマを決めることが実際のプロジェクト内容より難しいことすらある。作業の途中で誰かからフィードバックをもらうのも難しい。経験の多い人なら、そうしたフィードバックがなくても何かをうまく作り上げられると思うが、僕のような新人のへっぽこプログラマーには難しそうだ。オープンソース活動はこの点で、ポートフォリオ用プロジェクトより多くの利点を持っている。巨人の肩の上で仕事を始められるということだ。創造性がなくても、自分のプログラミングスキルを発揮でき、それを他人に見せてレビューも受けられる。
PyTorch のコード内を FIXME で検索した結果だ。あのうちいくつかはきっとそれほど難しくなく、初心者プログラマーでも貢献できるだろう。
実は、もっと重要なのは自分がした仕事についてレビューを受けられるという点だ。共同作業の経験が少ない僕のような初心者には、最も切実な部分だ。僕より経験の多い人に自分のコードを見せ、アイデアを交換する過程は大学では学べなかった。周りの学生たちは僕より圧倒的に実力が高いわけではなかったし、そうしてくれる教授や先輩たちは本当に忙しかった。実は僕がクソぼっちで友達がいなかったからかもしれない…
2. 気に食わないなら俺がやる
(僕は機械学習を勉強しているので、他の分野はどうなのか分からない)。TensorFlow も PyTorch も、それほど完璧ではない。それを作った人たちが優秀でないからではなく、優秀であるにもかかわらず。とにかく、TensorFlow である関数の Gradient が定義されていないというエラーに出くわしたときは、適当に微分してその式を実装すれば対処できるだろう。欠点は、僕がよく知らない分野については(VS Code で機能上の限界を見つけたのに、僕が Electron はおろか javascript すらやったことがないなら?)何の意味もないという点だ。
機能がなくてできないとき
Example
とにかく、僕が考えるオープンソースの長所を二つ話したので、実際の例を通じて本当にこうした長所が存在するのか、そして初心者プログラマーにどんな役に立つのか見てみよう。わざわざ初心者というレッテルを付けた理由は、僕が初心者だからだ。
問題発見
上の(2)と同じ状況だった。Deep generative ranking for personalized recommendation という論文を再現しようとしていた。論文で(僕が思うに)最大のコントリビューションは、user-item preferences を Beta distribution と考え、この分布自体を sampling して学習しようというアイデアだと思う。とにかく、一般的な Normal distribution とは違い、Beta distributinon の sampling を利用した分布の更新は少し厄介で、ガンマ関数の n 階導関数(Polygamma function)を必要とした。ところが PyTorch には、ガンマ関数の N’th order derivative が実装されていなかった(order of 1 までは実装されていた)。
やるべきことを定義する。
とにかく、TensorFlow ではこれがすでに実装されていることをすぐに見つけ、Scipy でも同じ機能を提供していることを知った。 その二つの実装がどちらも、cephes(https://www.netlib.org/cephes/) というライブラリの Copy-Paste だということも。
また、PyTorch の多くの部分が Cephes でできていることも分かった。なら、僕がやるべきことは Polygamma を Scratch から実装することではなく、適当に Cephes のコードを直すことだと思った。特に Polygamma の内容を理解する必要すらない簡単な仕事だった。
一番良かったのは、Polygamma の Interface がすべて作られていたことだ。n=1 の場合を除けば NotImplementedError を投げるようになっていた。
実装する & PR を飛ばす
この部分は簡単だった。C で書かれた library を template を使った関数に変え、いくつかの interface 用関数を実装した。少し複雑だったのは Cuda の実装だった。幸い、そのファイル内に一緒に実装されている他のコードをざっと見ながらほとんどコピペしたが、特におかしなところはなかった。
勉強になったのは、僕が考えていたよりテスト/意思決定/コードに対する基準がものすごく高かったことだ。実際、どこの会社でもみんなこうしているような気もするけれど。
コードレビューの一部。
おそらく、世界で最もコーディングがうまいグループの一つ(実は確かではない)の人からコードレビューを受ける経験は、何にせよ役に立つようだ。毎日これくらいのテンションでプログラミングに向き合っていたら、もっと優れたエンジニアになっていただろうに、無駄にした時間が惜しい。
結論(学んだこと)
- 勉強 & ポートフォリオの代わりになる
PyTorch の開発陣が使う Python のルールについて、ある程度理解したような気もするし、していないような気もする。 ディープラーニングだの強化学習だのという Fancy な言葉の裏には、実は80年代の物理学科/数学科/計算機科学科の大学院生が締め切りに追われながら作った Fortran/C コードが隠れているという事実に気づいた。
- 気に食わないなら俺がやる
ガンマ関数を PR してマージされる前に、結局、最初に実装しようとしていた論文を PyTorch で実装した。思ったほど性能が出ないことに気づき、ずいぶん時間を無駄にしたなと思ったが、まあ、これをやりながらたくさん学んだから、それでいいだろうと思った。
実際、残るのは自己顕示だけ…
実際、上でずっと話してきたすべての長所を除いたとしても、たまにやると面白いことだから ‘ㅅ’…
闲聊。
我经常听别人这么说。假设某件事会按 A、B、C、……、Z 的顺序进行,我会解释完 A,跳过 B、C、……、D 去解释 E,讲了半天 F 之后,又觉得好像需要 B,于是再回头解释 B。不只一两个人这么说,和我一起密切工作过的人似乎都说过类似的话,看样子确实有点问题。
感觉我在解释时,似乎预设了对方和我拥有同样的知识与局限。我觉得简单的部分,对方也觉得简单;我觉得难的部分,对方也觉得难。看来不只是在社会关系中,工作中共情能力也很重要。而且据说这种事就算努力也很难改善……..
对开源的一些个人想法
老实说,除去自我炫耀欲,我不太明白为什么要做开源。 站在公司的角度就更不明白了。即使读了好几篇类似Google 为什么要做开源的文章,我也不太能理解。尽管如此,我真的真的偶尔会做开源,理由如下。其实看起来很帅也是很大一部分原因,但除去这个
我认为开源的优点
1. 替代学习 &(资历较浅者的)作品集。
很多人会做玩具项目,把它用作作品集。我以前也是这样,但最近不太做了。学习某种东西时,小规模项目确实很有帮助。不过,这类项目最大的问题是,没有经验的话,就不可能做出有用的项目。首先,对于像我这样没有创造力、完全不适合第四次工业革命的人来说,找一个好主题甚至可能比项目的实际内容更难。做的过程中也很难得到别人的反馈。我觉得经验丰富的人就算没有这种反馈,也能成功做出某种东西,但对我这种菜鸟垃圾程序员来说似乎很难。开源活动在这一点上比作品集项目有很多优势。那就是可以站在巨人的肩膀上开始工作。即使没有创造力,也可以发挥自己的编程技能,把它展示给别人,还能得到 review。
这是在 PyTorch 代码中搜索 FIXME 的结果。其中肯定有一些并没有那么难,新手程序员也能够贡献。
其实,更重要的是能够让别人 review 我做的工作。对于像我这样协作经验很少的新手来说,这是最迫切需要的部分。把自己的代码给比我更有经验的人看、交流想法的过程,是我在大学里没学到的。我身边的学生实力并没有压倒性地强于我,而能这样帮助我的教授和前辈们又真的很忙。其实也可能是因为我是个死宅边缘人,没朋友…
2. 不爽我就自己干
(我在学习机器学习,所以不知道其他领域怎么样)。无论 TensorFlow 还是 PyTorch,都没有多么完美。不是因为做出它们的人不优秀,而是尽管他们很优秀,依然如此。总之,在 TensorFlow 中遇到某个函数的 Gradient 未定义的错误时,可以适当地求导,把那个公式实现出来解决。缺点是,对于我不熟悉的领域(比如在 VS Code 中发现了功能上的局限,但我别说 Electron,连 javascript 都没用过?),这就毫无意义。
因为没有功能而做不到的时候
Example
总之,既然已经说了我认为开源的两个优点,那就通过实际例子看看这些优点是否真的存在,以及它对新手程序员有什么帮助。之所以非要贴上新手这个标签,是因为我就是新手。
发现问题
当时就是上面(2)那样的情况。我试图复现论文 Deep generative ranking for personalized recommendation 。我觉得,这篇论文最大的贡献是把 user-item preferences 看作 Beta distribution,并对这个分布本身进行 sampling 来训练这一想法。总之,与一般的 Normal distribution 不同,利用 Beta distributinon 的 sampling 来更新分布稍微有些棘手,需要伽马函数的 n 阶导数(Polygamma function)。但 PyTorch 没有实现伽马函数的 N’th order derivative(只实现到了 order of 1)。
定义要做的事情。
总之,我很快发现 TensorFlow 已经实现了这个,也了解到 Scipy 提供相同的功能。还发现这两个实现都是从名为 cephes(https://www.netlib.org/cephes/) 的库里 Copy-Paste 过来的。
我也发现 PyTorch 的许多部分都由 Cephes 构成。那么,我觉得我要做的并不是从 Scratch 开始实现 Polygamma,而是适当地修改 Cephes 代码。这是一件甚至根本不需要理解 Polygamma 内容的简单工作。
最棒的是,Polygamma 的 Interface 已经全都做好了。除了 n=1 的情况以外,都会抛出 NotImplementedError。
实现 & 发 PR
这部分很简单。我把用 C 写的 library 改成了使用 template 的函数,并实现了几个用于 interface 的函数。稍微复杂的部分是 Cuda 实现。幸好,我粗略参考了同一个文件里实现的其他代码,基本上就是复制粘贴,也没发现什么奇怪的问题。
学到的一点是,他们对测试/决策/代码的标准比我想象的高得多。其实感觉其他公司也都是这么做的。
代码 review 的一部分。
能让世界上最会编程的群体之一(其实不确定)的人给自己做代码 review,这种经历无论如何似乎都是有帮助的。如果每天都以这种程度的劲头对待编程,我本可以成为更优秀的工程师,浪费掉的时间真可惜。
结论(学到的东西)
- 替代学习 & 作品集
我好像在某种程度上理解了 PyTorch 开发团队使用的 Python 规则,又好像没有。 我意识到,在深度学习、强化学习这些 Fancy 的词语背后,其实藏着80年代物理系/数学系/计算机系研究生被截止日期追着写出来的 Fortran/C 代码。
- 不爽我就自己干
在伽马函数的 PR 被合并之前,我最终用 PyTorch 实现了一开始想实现的那篇论文。发现性能没有想象中那么好,觉得自己浪费了很多时间,不过,想想在做这个的过程中学到了很多,那也就算了吧。
其实最后剩下的只有自我炫耀…
其实,就算除去上面一路讲下来的所有优点,偶尔做做也挺有意思的,所以 ‘ㅅ’…
Small talk.
There’s something I hear often. Say something proceeds sequentially as A, B, C, …, Z. Apparently, I’ll explain A, skip B, C, .., D, explain E, spend ages explaining F, then decide I seem to need B again and explain B. It isn’t just one or two people saying this; everyone who has worked closely with me says something similar, so it seems like I have a bit of a problem.
It feels like I explain things on the assumption that the other person and I have the same knowledge and limitations. A part that’s easy for me is easy for them too, and a part that’s difficult for me is difficult for them too. Empathy seems important not only in social relationships but at work as well. On top of that, apparently this sort of thing doesn’t improve much even if you work at it……..
Personal thoughts on open source
Honestly, aside from the desire to show off, I don’t really understand why people do open source. I understand it even less from a company’s perspective. Even after reading several pieces like Why Google does open source, I still don’t really get it. Nevertheless, the reasons I do open source very, very occasionally are as follows. Admittedly, looking cool is actually a big part of it, but aside from that
The advantages of open source, as I see them
1. It substitutes for studying & a portfolio (for someone with little experience).
Lots of people make toy projects and use them as a portfolio. I used to do that too, but I don’t much these days. It’s true that a small-scale project helps a lot when you’re learning something. But the biggest problem with projects like that is that, without experience, it’s impossible to make a useful project. First, for someone like me, who has no creativity and is entirely unsuited to the Fourth Industrial Revolution, choosing a good topic may be harder than the actual project itself. It’s also difficult to get feedback from someone while working on it. I think experienced people can successfully build something even without that feedback, but it seems difficult for a pathetic newbie programmer like me. Open-source activity has many advantages over portfolio projects in this regard. You can start working on the shoulders of giants. Even without creativity, you can exercise your programming skills, show them to others, and receive reviews.
These are the results of searching for FIXME in the PyTorch code. Some of them surely aren’t that difficult, and even a beginner programmer would be able to contribute.
Actually, the more important part is being able to get reviews of the work I’ve done. For a beginner like me with little experience collaborating, this is what I need most desperately. I didn’t learn at university the process of showing my code to someone more experienced than me and exchanging ideas. The students around me weren’t overwhelmingly more skilled than I was, and the professors or senior students who could have done that for me were really busy. Actually, maybe it was because I was a fucking loner with no friends…
2. If it pisses me off, I’ll do it myself
(I study machine learning, so I don’t know what other fields are like.) Neither TensorFlow nor PyTorch is all that perfect. Not because the people who made them aren’t excellent, but despite the fact that they are. Anyway, when you run into an error saying that the Gradient of some function isn’t defined in TensorFlow, you could differentiate it as appropriate, implement the resulting expression, and deal with it that way. The downside is that this means nothing for fields I don’t know well (what if I find a functional limitation in VS Code, but I’ve never used Electron—or even javascript?).
When it doesn’t work because the feature isn’t there
Example
Anyway, now that I’ve talked about the two advantages of open source as I see them, let’s use a real example to see whether these advantages really exist and how they help a beginner programmer. The reason I went out of my way to attach the beginner label is that I’m a beginner.
Discovering the problem
It was a situation like (2) above. I was trying to reproduce the paper Deep generative ranking for personalized recommendation . The paper’s biggest contribution (in my opinion) seems to be the idea of treating user-item preferences as a Beta distribution and training by sampling the distribution itself. Anyway, unlike a typical Normal distribution, updating a distribution using sampling from a Beta distributinon was a bit tricky and required the nth derivative of the gamma function (the Polygamma function). But PyTorch had not implemented the N’th order derivative of the gamma function (it was implemented up to order of 1).
Defining what needed to be done.
Anyway, I soon found that this had already been implemented in TensorFlow, and learned that Scipy provided the same feature. I also learned that both implementations were a Copy-Paste of a library called cephes(https://www.netlib.org/cephes/).
I also found out that large parts of PyTorch were made up of Cephes. So I thought my job wasn’t to implement Polygamma from Scratch, but to modify the Cephes code as appropriate. It was a simple job that didn’t particularly require understanding Polygamma at all.
The best part was that all of the Interfaces for Polygamma had already been created. Except for the n=1 case, they were set up to throw NotImplementedError.
Implementing it & firing off a PR
This part was simple. I turned the library written in C into a function using templates and implemented a few functions for the interfaces. The slightly complicated part was the Cuda implementation. Fortunately, I looked roughly at the other code implemented alongside it in the same file and almost entirely copied and pasted it, and there wasn’t anything particularly strange.
What made it educational was that their standards for testing/decision-making/code were tremendously higher than I’d thought. Though, actually, it seems like everyone does this at any company.
Part of the code review.
Getting a code review from someone in one of the groups that is probably best at coding in the world (I’m actually not sure) seems helpful one way or another. If I had approached programming with this much intensity every day, I would have become a better engineer; it’s a shame how much time I wasted.
Conclusion (what I learned)
- It substitutes for studying & a portfolio
I feel like I sort of understand the Python conventions used by the PyTorch developers, and also like I don’t. I realized that behind Fancy terms like deep learning and reinforcement learning, there is actually Fortran/C code written by physics/math/computer science graduate students in the ’80s while being chased by deadlines.
- If it pisses me off, I’ll do it myself
After submitting the gamma function PR and before it was merged, I ended up implementing in PyTorch the paper I had originally wanted to implement. I realized the performance wasn’t as good as I’d expected and thought I’d wasted a lot of time, but, well, I learned a lot while doing this, so I figured that made it okay.
In fact, all that remains is showing off…
Actually, even aside from all the advantages I went on about above, it’s something fun to do once in a while, so ‘ㅅ’…