잡담
추천 시스템 연구하는 곳에서 나와서 왜 추천시스템 리뷰… ‘ㅅ’… 관련 프로젝트를 하나 진행하기로 해서, 추천 시스템 공부를 좀 해야 할 필요성을 느끼기도 했고, 음… 더 중요한 것은, 간단한 모델의 Clever한 사용이 좋은 결과를 만들어내는 경우의 모범적인 케이스라, 공부하면 좋을 것 같다고 생각했다.
나도 언젠가 이렇게 멋진 일을 하고 싶다.
Introduction
2억명이 넘는 유저와 삼십억이 넘는 아이템을 유저에게 리얼타임으로 추천하기 위해, Pinterest에서는 Graph 기반의 새로운 추천, Pixie를 제안했다.
Pinterst는 유저가 좋아하는 아이템(사진)에 Pin을 남기는 방식으로 유저와 아이템이 interaction한다. 유저는 자신이 Pin한 사진들을 Board를 만들어 그곳에 저장할 수 있다. 즉, Board는 비슷한, 혹은 관련이 있는 pin의 집합이라 생각할 수 있다. 예를 들어서, 하츠네 미쿠의 사진을 모아놓은 보드가 있을 수 있고, 보드 안의 각 핀은 하츠네미쿠의 사진들일 것이다. 각각의 보드는 유저가 생성한 큐레이션으로 생각할 수 있고, 하나의 사진은 여러 보드, 즉 큐레이션에 포함될 수 있다.
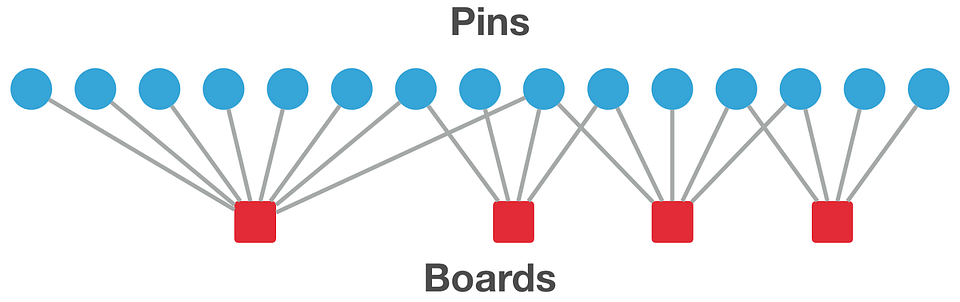
pin과 board 사이의 biparite graph 관계
Pinterest 내의 보드들과 사진들을, 하나의 그래프로 생각할 수 있다. 특히, 이는 Bipartite Graph로서, 하나는 보드, 하나는 사진, 그리고 각각 보드와 사진을 잇는 에지는 유저가 남긴 pin이 된다. Pixie는 이 Graph를 random walk하는 알고리즘을 이용해, 추천을 할 수 있다고 주장하고 있다.
Pixie Random walk
Pixie Random walk 알고리즘은 상당히 쉽다! Deep learning을 사용하는 것도 아니고, 간단한 Random walk on graph 알고리즘에, 여러 Clever한 heuristic을 적용하는 것으로 상당히 우수한 결과를 만들어내고 있다는 점이 놀랍다. 우선 Random walk 알고리즘이 무엇인지 후 설명한 Pixie에 적용된 여러 heuristic을 살펴보자(논문에서도 이렇게 소개되어 있다).
Basic Random walk
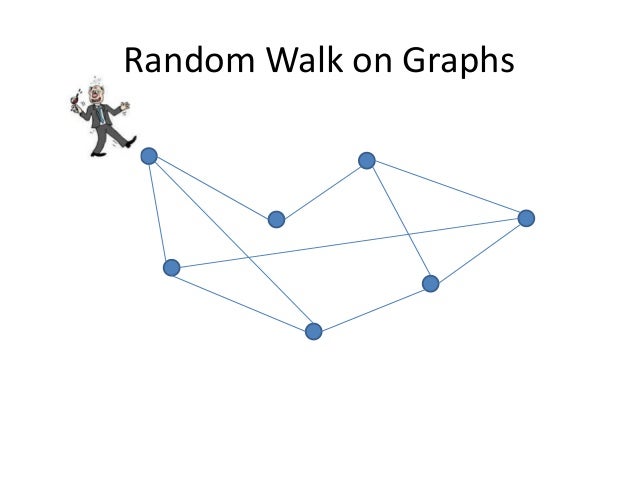
Random walk on graph란 , 그래프의 한 노드에서 출발해, 인접한 노드로 아무렇게나 쭉 이동하는 것이다. 그리고, $K$번째 스텝마다 방문한 노드를 기록한다. 처음에 정했던 N번의 step이 끝난 후, 노드가 기록된 횟수만큼을 각각 노드의 가중치로 리턴해주는 방법이다. 한번의 random walk이 아니라, query node $q$에서 출발하는 Random walk를 여러 번 진행한 뒤, 그 평균을 리턴할 수도 있다.
말보다, 오히려 Pseudocode로 보는 것이 간단하다.
def random_walk(query_node q, edges E, visit_count N):
tot_steps = 0
visit_counter = dict()
while True:
curr_node = q
step_size = sample_random_walk_length()
for i in (1,... step_size):
curr_node = E[curr_node].random_neighbor()
visit_counter[curr_node] += 1
tot_steps += step_size
if tot_steps > N:
break
return visit_counter
Pinterest algorithm에서는 board, pin으로 이루어진 bipartite graph이며, board의 방문은 고려하지 않는다. 알고리즘을 보드를 반영하지 않게 고쳐보자.
def basic_pixie_random_walk(query_pin q, edges E, visit_count N):
tot_steps = 0
visit_counter = dict()
while True:
curr_pin = q
step_size = sample_random_walk_length()
for i in (1,... step_size):
curr_board = E[curr_pin].random_neighbor()
curr_pin = E[curr_board].random_neighbor()
visit_counter[curr_pin] += 1
tot_steps += step_size
if tot_steps > N:
break
return visit_counter
이러한 형태의 함수를 이용해, 주어진 query pin $q$와 연관성이 높은 pin의 리스트를 만들 수 있다.
Basic Random Walk의 개선
다만, 이 함수의 추천이라는 관점에서의 문제점이 생각나지 않는가?
(1) 이런 형태의 Random walk는 개인화된 추천을 제공하지 못한다. 또한, Random walk 알고리즘, 혹은 PageRank 알고리즘의 특징인, (2) Popular node의 relevancy가 (추천을 위해 사용하기에는 너무) 높게 나온다는 문제점이 있다. (3) 그래프가 너무 커져서, 추천을 만들어내는 데에 오래 걸릴 수 있다.
Pixie는 단순하지만, 우아한 방법을 이용해 이러한 문제를 회피한다.
유저와 관련있는 에지에 가중치 부여하기
Random walk 도중, 다음으로 이동할 Pin 혹은 Board를 선택할 때, 이를 반영하게 만들 수 있다. Pixie는 이 방법을 통해 유저에게 개인화된 추천을 제공한다. 그래프에서 유저에게 관련이 있는 부분을 강조하는 것으로, 추천의 개인화, 퀄리티, 관심사 모든 측면에서 더 좋다고 한다. 각 pin, board, 그리고 유저에게는 토픽이나, 언어와 같은 특징이 존재하는데, 서로 매칭하는 핀으로 이동할 확률을 높여주는 방식이라고 주장하는데, 구체적인 방법은 나와있지 않은 점이 아쉽다.
유저가 본 여러 핀을 가중치를 이용해 추천에 사용하기
유저에게 추천을 하고 싶은데, 위에서 본 random walk 알고리즘은 개별 pin에 대해 동작한다. 유저가 클릭한 pin은 많을 테니, 유저와 interaction이 있는 pin들을 잘 조합해서, 유저에 대한 추천을 만든다.
여러 pin을 섞어서 추천을 할 때, Pixie에서 중요하게 여기는 점은 다음과 같다.
Query pin의 가중치
- interaction의 종류
유저가 pin을 저장했을 수도 있고, 단순히 클릭했을 수도 있다.
- interaction한 후 시간이 얼마나 지났는지
30초 전에 클릭한 핀과, 3시간 전에 클릭한 핀 중, 유저에게 추천할 때 중요한 것은 당연히 30초 전에 클릭한 pin일 것이다.
이를 이용해 각 query pin $q$마다 의 가중치$w_q$를 만들어준다.
- 속도
위에서 언급을 잘 하지 않았는데, 논문의 제목에서도 알 수 있듯이 Pixie는 Web-Scale의 추천을 하기 위해 많은 트릭을 사용하고 있다.

실제로, query pin의 언어에 상관없이, 모든 경우에서 target language(유저가 사용하는 언어)가 추천될 확률을 높였다. query pin이 영어인 경우, 추천 결과가 유저의 언어 설정과 같을 확률이 상당히 올랐다. 또한, 유저의 입력 언어가 유저가 사용하는 언어 설정과 같은 경우, 추천의 결과도 모두(100%) 동일했다.
Adjusting random walk size
Degree가 높은 node일수록, 수렴하기 위해 더 많은 Random walk이 필요하다. 따라서, node의 Degree에 맞게 random walk의 size를 조정해주는 것이 좋다.
\[s_q = Degree(q)(C - \log(Degree(q))\]where $C = max_p\in P, P$ is the set of all pins in the graph
위에서 정의한 가중치를 합쳐서, 개별 Query에 대한 Random walk의 step size를 계산한다. 한 query pin $q$가 Random walk을 할 때, Random walk의 Step size $N_q$는 다음과 같이 정의한다.
\[N_q = w_q \frac{s_q}{\sum_{s'q \in Q}s_q'}\]where $Q$ is the set of query pins, and $N$ is default random walk step size.
Aggregating each pin’s random walk results
query pins $q_1, q_2, …q_k$가 있을 때, 여러 query pin과 관계가 있어 많이 visit된 pin의 가중치를 novel하게 높이는 방법을 제안했다.
\[V[p] = (\sum_{q \in Q}{\sqrt{v_q[p]}})^2\]where $V_q[p]$ is visit count during random walk from query pin $p$, $V[p]$ is combined visit count of $p$.
식을 잘 살펴보면, 오직 한 query pin $q$에게만 방문된 pin $p$의 visit count는 변하지 않는다. 하지만, 여러 핀들이 $p$를 방문한 경우, 그 pin의 visit count는 더 커지게 된다.
Early stopping
추천은 일반적으로 Top K개의 아이템을 뽑는다. Random walk를 하던 도중에, $n_p$개의 pin이 $n_v$ 회 이상 방문된다면, random walk를 멈춰도 random walk를 더 오랫동안 돌린 결과랑 크게 차이가 나지 않는다. 이는 Pixie 알고리즘을 2배 가까이 빠르게 한다.

실제로, $n_p$나 $n_v$의 값을 적당히 설정하면 80-90% 이상의 결과가 겹치며, 성능은 2-3배 빨라지는 결과를 만든다.
위의 내용을 반영한 Pixie Random Walk 알고리즘과, 이를 이용한 추천 알고리즘의 Pseudocode는 다음과 같다.
def pixie_random_walk(User u, query_pin q, edges E, visit_count N, terminate_step v, terminate_walk p):
num_high_visited_pins = 0
tot_steps = 0
visit_counter = dict()
while True:
curr_pin = q
step_size = sample_random_walk_length()
for i in (1,... step_size):
curr_board = E[curr_pin].personalized_neighbor_wrt(U)
curr_pin = E[curr_board].personalized_neighbor_wrt(U)
visit_counter[curr_pin] += 1
if visit_counter[curr_pin] == v:
num_high_visited_pins += 1
tot_steps += step_size
if tot_steps > N or num_high_visited_pins > p:
break
return visit_counter
def pixie_recommendation(query_pins Q, weight W, edges E, user u, default_step_size N):
# v, p = predefined terminate step and terminate walk constant
for q in Q:
N_q = # (Adjusting random walk size) 부분의 식에 의해 계산됨
V_q = pixie_random_walk(u, q, E, N_q, v, p)
V = # V_q들을 (Aggregating each pin's random walk results) 부분의 식을 이용해 합침.
return V
Graph Pruning
Pixie는 pin-board graph를 추가적으로 pruning하면서 성능과 속도 둘 다 개선시킨다. 첫번째로, 각 board 내의 content의 diversity를 계산한 뒤, diversity가 높은 board를 제거한다. 그 다음으로는, board의 주제와 맞지 않는 pin들을 제거한다. 구체적으로는 다음과 같다.
- Similarity 계산으로는 각 pin의 description(text)의 LDA topic modelling을 이용했다.
Pruning boards
Board에 최근에 추가된 pin들의 LDA 결과를 입력으로 보드의 Topic distribution을 구한 뒤, entropy를 board의 entropy로 생각한 후, large entropy를 갖고 있는 board를 제거한다.
Pruning edges
각 pin$p$의 degree $degree(p)$ 개 중, $degree(p)^\delta$개만을 남기고 제거하는데,
위에서 계산한 보드의 Topic distribution과 각 pin의 topic distribution을 계산한 후, 두 분포간의 cosine similarity가 낮은 $degree(p) - degree(p)^\delta$개의 board로 이어지는 edge를 제거한다.

위 그래프에서 알 수 있듯, 적당한 크기의 pruning factor는 추천의 성능을 향상시키며,

추천 생성 또한 빠르게 할 수 있게 만든다.
이 과정을 거치면 또한, 70억개가 넘었던 그래프 노드의 수를, 약 10억개의 board와 20억개의 pin, 100억개가 넘었던 edge들을 약 170억개 이내로 줄일 수 있다. 줄여도 어마무시한 사이즈….
실제 추천 사용 사례
홈 피드

핀터레스트 어플리케이션의 메인 페이지에는 몇 가지의 pin 추천이 뜨게 되는데, 이 추천을 유저의 액션이 생길 때마다 새롭게 추천을 생성해서 보여준다. 당연한 결과겠지만, 오프라인 추천 생성보다 성능이 훨씬 우수하다고 논문에서는 주장한다.
유사한 핀 더 보기(연관있는 핀 더 보기)
추천 시스템의 가장 흔한 사례라고 할 수 있겠지만, Pinterst는 사진이라는 특징을 살려, 유사한 pin을 만드는 더 좋은 heuristic을 적용했다. Random walk의 길이가 길면 조금 더 다양한 pin이 추천될 것이다. 유사한 핀 더 보기에서는 다양한 pin 보다는 쿼리 pin과 비슷한 pin을 보여주는 것이 더 효율적이라고 Pinterest는 생각했고, 실제로도 그렇다고 한다.
이외에도, board recommendation, 그리고 훨씬 더 많은 추천에 Pixie를 이용하고 있다.
References:
[1] Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time, https://arxiv.org/abs/1711.07601
[2] An update on Pixie, Pinterest’s recommendation system https://medium.com/pinterest-engineering/an-update-on-pixie-pinterests-recommendation-system-6f273f737e1b