추천 시스템 모델을 만드는 사람에게 (생각보다 자주 벌어지는) 기분 나쁜 상황
모델을 열심히 만들었다. 근데 학습이 이상하게 느리다.
그래서 nvidia-smi를 눌러서 GPU 사용량이 얼마나 되나 확인해보면 utilization이 낮다. 대체로 0-10% 사이를 오가며, 아마도 내 딥러닝 모델이 계산을 하고 있을 것 같은 순간에만 GPU-Utilization이 20%를 넘는다.
사실, 이는 데이터의 형태를 적당히 바꿔서, GPU 메모리로 올리는 시간이 모델이 실제로 계산하는 시간보다 길다는 의미다. 이를 해결하기 위한 방법이 사실 많이 있다. 한가지 소개하자면 NVIDIA Merlin DataLoader같은 것이 있다. 대강 확인한 바로는 정확히 어떻게 하는지는 잘 모르겠는데, 빈 시간에 데이터를 전처리해서 조금씩 올려놓는 것 같다.
저기 코드를 읽어보고, NVTabular같은 복잡한 걸 쓰지 않더라도 잘 생각해보니 나도 비슷한 걸 대충 따라할 수 있을 것 같았다.
AutoEncoder 기준으로, 들어가는 데이터는 user-item matrix의 row들이다.
우리가 할 연산은,
- sparse matrix rows -> dense rows (torch.FloatTensor in cpu)
- dense rows (torch.FloatTensor in cpu) -> dense rows (torch.FloatTensor in gpu)
- 모델 계산 이다.
movielens-20m 데이터의 임의의 500 로우(배치 한 번이라고 생각하자)를 가져와서 대강 시간이 얼마나 걸리나 계산해보자.
sparse to dense
# sparse to dense
%%timeit -n 5 -t 1
mat[:500].toarray()
52.8 ms ± 893 µs per loop (mean ± std. dev. of 7 runs, 5 loops each)
CPU to GPU
# cpu to gpu
dense_array = torch.from_numpy(mat[:500].astype(np.float32).toarray())
...
%%timeit -n 5 -t 1
dense_array.cuda()
16 ms ± 1.56 ms per loop (mean ± std. dev. of 7 runs, 5 loops each)
Model calculation
y_pred = model.forward(rows)
model.zero_grad()
lf = loss_function(...)
lf.backward()
optimizer.step()
19.7 ms ± 7.42 ms per loop (mean ± std. dev. of 7 runs, 5 loops each)
여기서 보면, 데이터를 변환하는 데 가장 큰 시간이(모델 계산의 3배), 그리고 cpu의 데이터를 gpu로 보내는 데에 모델 계산과 거의 동일한 시간을 쓰고 있다는 것을 알 수 있다. 일부러 batch size를 크게 500을 준 것을 감안하면, 정말 많은 시간을 의미없는 데에 쓰고 있다고 할 수 있다.
개선책 1
sparse -> dense 연산을 가능하면 한 번에 한다. 그렇게 단순한 데이터셋 naiveDataset을 만들어보면 다음과 같다.
물론 가장 좋은 방법은 sparse input을 고려해서 autoencoder를 구현하는 거지만, 그게 말처럼 쉽겠는가.
class naiveDataset(Dataset):
def __init__(self, mat):
self.mat = mat
def __len__(self,):
return self.mat.shape[0]
def __getitem__(self, i):
return self.mat[i]
# Dataloader
DataLoader(naiveDataset(tr.toarray()), batch_size=250, shuffle=True, num_workers=8)
이래도 느려서, 다음과 같은 일을 더 해줄 수 있다. 사실 더 좋은 방법이 있을 것 같아서 다른 사람들의 의견을 묻고 싶은 것도 있다. cuda로 데이터를 미리 보내주는 스레드를 만드는 것이다.
class BigBatchIterator(object):
def __init__(self, mat, batch_size=2**13):
self.mat = mat
self.indices = shuffle(np.arange(mat.shape[0]))
self.curr_idx = 0
self.big_batch = batch_size
self.batch_queue = queue.Queue()
self.next_stop_iter = False
...
def __next__(self):
if self.next_stop_iter:
raise StopIteration
rn = 0
while (self.batch_queue.qsize() <= 16) and (rn <= 4):
batch = (self.big_batch * self.curr_idx, self.big_batch * (1 + self.curr_idx))
if batch[0] >= self.mat.shape[0]:
break
threading.Thread(target=async_run, args=(self.batch_queue, self.mat, batch)).run()
self.curr_idx += 1
rn += 1
ret, bs = self.batch_queue.get(block=True)
if bs[1] >= self.mat.shape[0]:
self.next_stop_iter = True
return ret
def BatchIterWrapper(torch_mat, big_batch_size=5000, small_batch_size=250):
iterator = BigBatchIterator(torch_mat, batch_size=big_batch_size)
for k in iterator:
for r in range(0, big_batch_size, small_batch_size):
yield k[r:r + small_batch_size]
이렇게 하면 뭐 이렇게 계산할 수 있다.
for rows in BatchIterWrapper(tr_torch, 10000, 500):
# rows는 이미 gpu에 저장된 tensor이다.
# 업데이트 루프
model.forward(rows)
...
VAE 성능 비교
- VAE 구현체의 출처: https://github.com/younggyoseo/vae-cf-pytorch
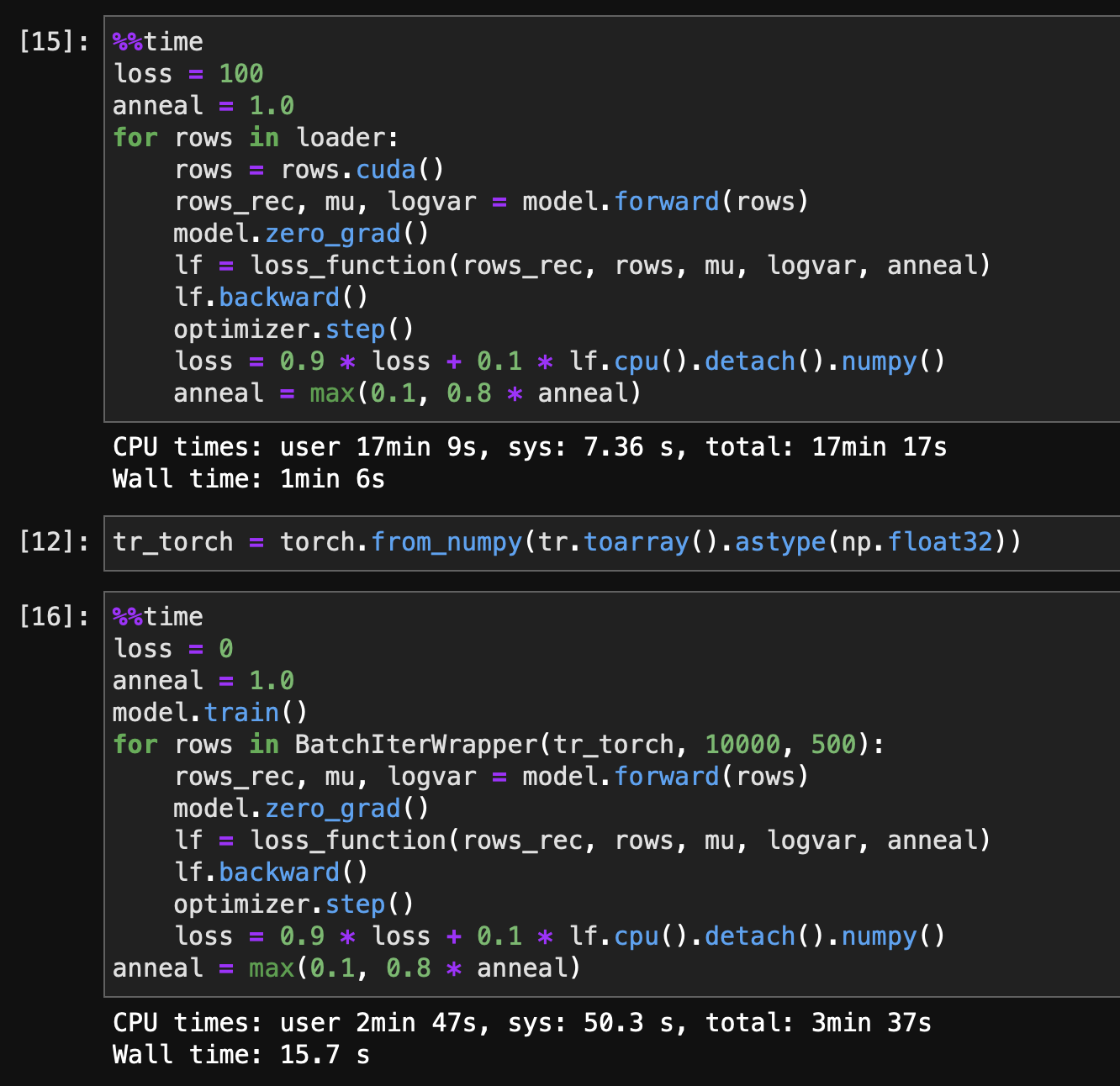 MovieLens 20m 데이터셋을 batch_size 500으로 한 epoch 학습하는데, naiveDataset은 1분 6초가 걸리는데 비해, BatchIterWrapper는 15초면 학습할 수 있었다.
MovieLens 20m 데이터셋을 batch_size 500으로 한 epoch 학습하는데, naiveDataset은 1분 6초가 걸리는데 비해, BatchIterWrapper는 15초면 학습할 수 있었다.
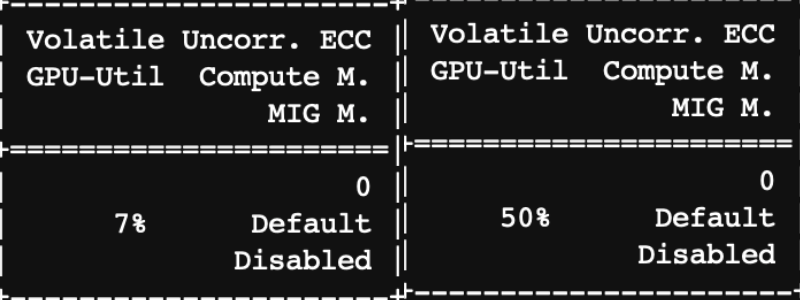
그리고 처음에 보고 빡친 더럽게 낮은 gpu utilization도 훨씬 높아졌다!!!
결론
병렬로 데이터 전송을 잘 할 수 없을 것 같아서 해 볼 엄두를 못 내고 있었는데, 막상 대충 해도 꽤 많이 오르더라라는 점을 알아냈다. 100%의 솔루션이 아니어도, 50% 정도만 할 수 있어도 일단 해 보고 고민하는게 좋다는 얘기일까.